On-the-fly Aggregations part 1
22 Jan 2018 | by Chris Roe
Learn how you can accelerate your data aggregation practices while reducing unnecessary overheads – discover the new on-the-fly functionality from Apteco.
The emergence of aggregation
Practices of aggregating customer data are continuing to provide benefits across marketing and data analysis. The ability to quickly summarise transactional data for an individual is a very powerful tool for those looking to simplify their data analysis, and one that can be applied to various communication opportunities.
In the first of this two part series, we’ll be looking through some common examples of how analysts and marketers can aggregate their customer data more efficiently than ever before with ‘on-the-fly aggregations’.
Achieving aggregation with Apteco FastStats®
Some typical areas that require the aggregation of customer data include (but are of course not limited to):
- Number of transactions in the last year
- Average transactional value per customer
- Date of last purchase for an individual customer
All of these are common types of aggregation that have been achievable using Apteco FastStats® for many years, through either one of two methods:
- Using RFV selections to select customers whose average transactional value was over £1000 through the ‘Apply RFV’ option in the Selection Tree, before entering the desired parameters for the variable and the amount in the Value section.
- Creating Virtual Variables (or VVs) using the Wizards, consolidating these aggregations into new variables that can be used flexibly throughout the application. For example, to output the average transaction amount in a Data Grid, or to use as a statistic in a Cube.
In many cases the creation of these Virtual Variables is sensible, often representing customer attributes that are going to be used regularly. It is useful to have these aggregated results readily available in the System Explorer, so that, should they have to be brought into your analytical workflow, it can be done as efficiently as possible.
In other instances there may have been necessary intermediate results for a particular piece of analysis that you may never use again. In these cases, the variables in question often go on to be forgotten about, languishing in the System Explorer with a name that doesn’t adequately describe its purpose, making it difficult to find if you ever do end up needing it further down the line.
The time involved with creating VVs makes the update process unnecessarily time-consuming, adds extra complexity into System Explorer navigation, and will likely give you more variables than you need.
But now, following the implementation of ‘on-the-fly’ aggregations, virtual variables can be evaluated from the point at which they are needed to be used during analysis, helping you to reduce excess overheads.
Instead, aggregations are created and then combined within the Expression tool. This simplifies the process by granting you the flexibility to use aggregated results within the analytical workflow.
A simple example
Let’s say you want to select the top 10% of people by the difference between the most and the least they have spent on a holiday booking.
The old solution would have involved creating an expression of the form:
[Maximum Cost] – [Minimum Cost]
After creating a Virtual Variable using the Aggregation wizard to represent Maximum[Cost], the next step would be to repeat this process to create the Minimum[Cost]. It would then be necessary to add both those variables to an expression. Finally, you would have to create a TopN on a selection, and drag the expression in before choosing the Top 10% of people.
This process is just as time-consuming as it sounds, and only creates intermediate results. It also tends to result in the creation of two new variables that won’t be required for future analysis work.
New Solution – we now define aggregations directly within the expression tool. An ‘Add Aggregation’ button is on the Expression toolbar which creates a tab in the Expression (just like if you add a query or cube to an expression) in which the definition of that aggregation can be defined. Here is the definition for the Maximum(Cost) aggregation:
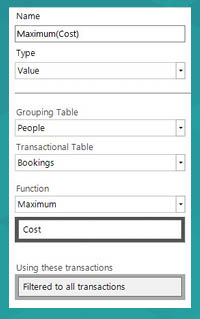
As you can see, the expression is very similar to the variable-based one:

The expression can be tested by previewing it from within the tool. We can see the final result and all the aggregations that were contained within it.
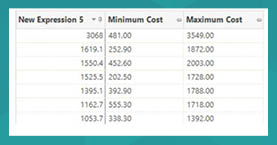
The expression can then be utilised within the TopN to solve this particular question, or could have been used in any of the other tools that support the use of expressions (as columns in a data grid, as dimensions or statistics in a cube etc).
Other examples
As well as numerical aggregations, we can also create date or selector aggregations, using the Recency aggregation type.
So, looking back at the example of holiday bookings, how could we select people who have had more than 3 bookings, such that their first and last destination is the same?
Old solution – This would have required us to create 3 Virtual Variables before combining them within an Expression to achieve the result.
The Recency aggregation type is very similar to the existing Recency wizard. It allows you to order your transactions by an ordinal variable and then pick a specific data item from a specific record.
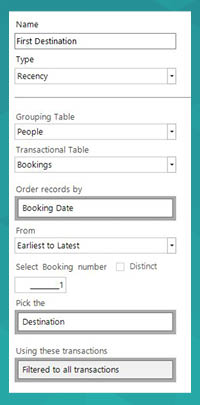
In this instance we are returning a Selector data type, so we need to wrap this in one of the Selector functions and test for equality. The full expression is shown below – each aggregation has been named within the expression to ensure that its purpose is clear.
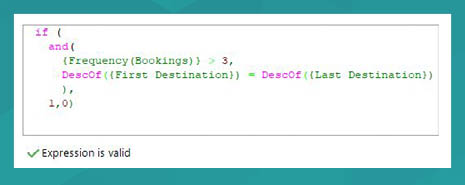
Testing the expression shows some records for which the condition holds and others where it doesn’t. Our expression is behaving as we expected it to.
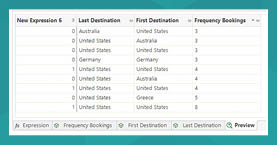
Further Examples
In the two examples given above, the aggregations were based upon the full set of transactional records. However, each aggregation type allows a selection of transactional records to be specified. An example of how this could be used is that you may create an expression to return the difference between the average order value in the last 12 months and the previous 12 months.
In this initial version we have supported almost all of the aggregations that could have been created using the existing RFV wizards. Furthermore, we have supported the Maximum Distinct Count and the Rank Coefficient aggregations that are available in the Data Grid aggregation functionality. Finally we have also supported a Select Nth Distinct extension to the Recency aggregation.
We hope the developments detailed in this blog post will empower you to simplify your processes of creating expressions, allowing you to reference aggregation results swiftly and easily.
Discover the full potential that can be realised from smart usage of your transactional data. Download: Best Next Offer: Think Ahead with Predictive Analytics
