:format(webp))
Sequencing transactions through pattern matching – part 3
Discover how to answer analytical questions with pattern matching
In previous blog posts (see part 1 and part 2) we introduced the idea of pattern matching as a way of understanding sequences of transactions for a customer. This powerful technique can be used to both select from, and analyse a customer database and provide insight into interesting transactional behaviour.
We looked at how we could define and look for patterns in consecutive transactions. We described a number of wildcards that could be used to provide a particularly powerful framework for this type of analysis. By allowing the user to choose a value to return from that matched pattern we enabled numeric, date or string results to be created and then used in other FastStats tools (e.g. to select on, or to display in a data grid).
In all these cases the algorithm terminated on the 1st time that it matched the pattern it was aiming for. There are many use-cases where this may not be the most desirable behaviour. For instance, a holiday company may want to select people who have been to Australia-United States-Greece in the last 12 months. If a person had this sequence 10 years ago, and also 10 months ago then it would be the first (oldest) of these patterns that would be matched – and the person would not be selected. In this example, we would want to select based upon the Last match, and not the first match (*1).
In this blog we explain how we can go about doing this, and illustrate some of the analytical questions that we can now seek to answer.
Pattern matching – returning the Nth pattern
Returning the first matched pattern is relatively straightforward. We can simply break off from scanning through the transactions as soon as we know we have encountered the pattern we are looking for. In some of the more generalised cases discussed below we have to scan through all of the transactions, find and store all the matched patterns and then sort them in to a specific order before extracting details of one of the matched patterns.
The user will get presented with the following choices in the Pattern Match controls. The bottom value is the pre-existing choice of the value from the matched pattern to return. The top 3 controls give the user the ability to specify which particular pattern they want to match.
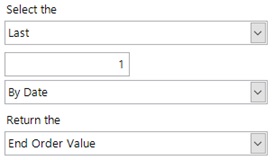
The choices are as follows:
Direction – First/Last. This controls whether we want to return the pattern as counted from the start of the transaction list, or from the end of it. A common requirement here would be to look for the Last time a pattern has occurred.
Number – 1 or more. This has to be a positive integer value, and will return this pattern number from the sorted list. If the person has had less than this number of matches then a missing value will be returned.
Sort metric –This defines how we are going to sort the set of matched patterns. There are 3 options:
- The default value is to sort the patterns in the order they are encountered in the sequence variable (typically in date order).
- We can also order our pattern matches by the difference between the start and end sequence values. Typically when ordering by date variables this will be the number of days between the start and end of the pattern. With this option we can then answer questions of the form: ‘Find the shortest number of days in which a customer has bought product A then B’.
- The final option is to sort by the number of transactions making up the sequence. This option is only relevant if the pattern contains the * wildcard (e.g. A*B) because in this case the patterns matched may be of different numbers of transactions. In this way we can find the shortest number of transactions taken to match A and then B in a sequence.
Examples
Find all the people who have made a booking to USA then to Australia and then to USA again within a 10 day period. To do this, we can find the smallest order span for all of the matched (USA-AUS-USA) patterns.
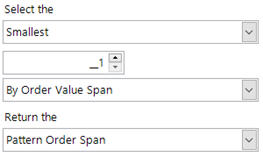
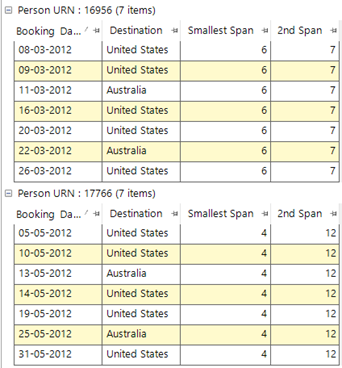
We can then add this aggregation expression to a selection and select upon this numeric value to find the 55 people in our Holidays system that have had the transactional behaviour required. Two of those people and their transactions are shown in the grid below.
Example 2 – Find people who have been to USA-AUS-USA in the last 3 months.
For this example we use the same pattern values as above and then select the start date of the last time that the USA-AUS-USA was matched, by using the settings below.
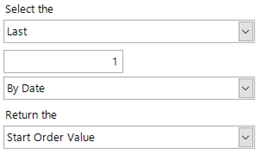
We can then expand the expression to:
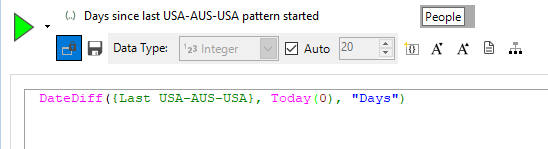
This expression can then be added to a selection and we can select upon the resulting value from the above to be < 90 days. This will then give us all the people who have undertaken the USA-AUS-USA pattern within roughly the last 3 months.
Football examples
What is the longest time between losses for an international football team?
There are a number of issues here in terms of identifying the particular time in which this has happened. They are:
1 – to restrict this analysis to international teams and their matches we will have to use a transactional filter selection restricting the transactions to international matches only.
2 – we do not know the length of the sequence of matches here, because we are only interested in the fact that a series of draws or wins is bookended by two losses. The pattern therefore will be best expressed as ‘L * L’ (i.e a loss, then some results, then another loss). NB – there are existing other methods to do this (see N) but these will fall foul of the problems below.
3 – the existing pattern match technique will not help solve this problem as it will stop on the first occurrence of L*L and return the number of days between those two losses. However, a team will have had a number of losses over time and we do not know which pair of losses we are interested in. We will therefore sort and choose the ‘Largest 1’ of such matches, using the matching strategy below.
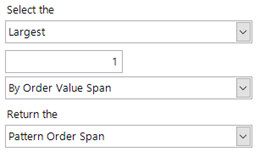
If we then add this information to a data grid and then order them by this aggregated value then we see the top few teams as below.
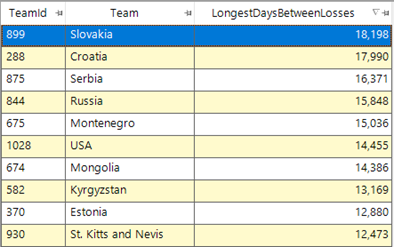
This seems on the face of it quite astonishing. Firstly, that there aren’t many of the international footballing powerhouses in the list above, and secondly that the values are extremely large. The 18,198 days of Slovakia’s longest time between two losses is nearly 50 years! Let us take a closer look at the match data to sense check this result.
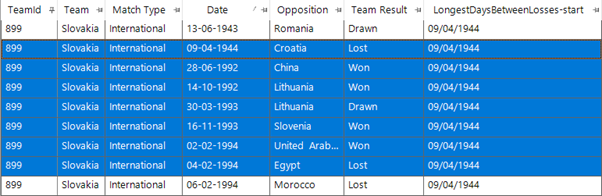
So, the data looks accurate, they didn’t play a match for 48 years – but this isn’t really quite what we would really want as there are large gaps between the matches. We would have to choose a way of saying that teams should have no large gaps between matches. We can do this using the ‘Max Days between Transactions’ property. If we set this to 365 days then this will ensure that a team can only have a valid sequence of matches if they have had at least one match every year.
This then gives the following results which does have some teams that we might have expected to see in the top 10 by such a metric:
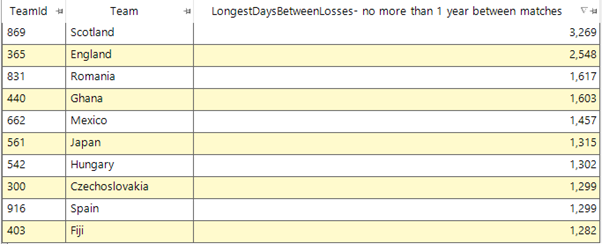
This can be corroborated by delving further into Scotland’s almost 9 year non-losing streak and finding that it started with a loss on 05/04/1879 and then had only wins and draws until the next loss on 17/03/1888.
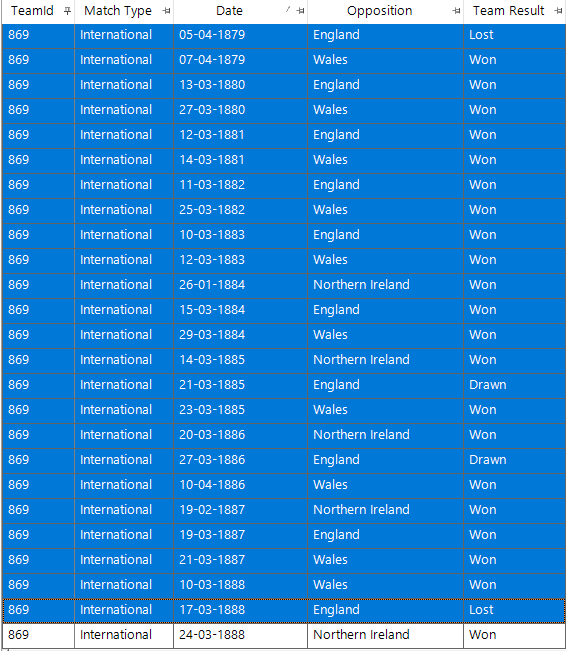
In our dataset at present there are 761 matches played by Scotland, of which they have lost 235. To find the particular transaction set above the algorithm has identified the length of time between each of the 234 pairs of adjacent losses, sorted them by the length of time between them, and then returned the biggest such value.
Conclusions
This blog post has discussed functionality that has been introduced in the Q4 2019 releases. These new features enable a wider range of pattern matching scenarios to be expressed in FastStats, to analyse or select people by sequences of transactions. It has also enabled us to delve even further into football statistics!
References
- Previous blogs on pattern match analytics
- *1 – note that one way around this issue (before the Q4 2019) release would be to add a transactional filter selection so that only transactions in the last 12 months were considered. An alternative approach that can work for many examples is to reverse the pattern, and reverse the order of the transactions.
This is the third part of a series with four parts. Click here to access the last part of this blog series.
If you would like to learn more about how to get the most from your data and stay ahead of your competitors download our eGuide.